
Update: I felt my original explanations were a little lacking in places, so I’ve added to the post…
In recent years, the public has seen remarkable advances in digital imaging technology. In the past few months, for instance, Lytro has introduced its fascinating “light field camera“, a camera which allows one to focus photographs after they’ve been taken! Their gallery of pictures, which one can dynamically adjust the focus of, are quite spectacular.
The light field camera works its magic by recording not only the color and intensity of incoming light arriving at an array of digital sensors, but also the direction of individual light rays. This directional information allows one to virtually adjust the focus of an image, change the perspective of the image, or even construct a fully three-dimensional image.
In simplest terms, the light field camera captures more information than an ordinary digital camera. One might consider this a new stage in a general trend in digital photography: the first prototype digital camera built by Sony in 1981 possessed 720,000 pixels (light sensors), whereas modern digital cameras possess anywhere between 12 million and 16 million pixels. Newer cameras gather more information in a single photograph, and this allows the production of images of increasingly higher resolution.
Another recent discovery, unnoticed by the public, will likely have an even greater influence on optics and imaging than the light field camera. The new technique associated with it, called compressive sensing, could result in newer cameras producing higher-quality images but having less pixels than current models — and could even result in high-resolution cameras with a single pixel!
At the recent Optical Society in America’s Frontiers in Optics meeting in San Jose, compressive sensing made the list of “hot topics in optics” for the second year in a row. It’s too early to determine exactly how much of an impact the technique will have on modern technology, and when it will have that impact, but it is a fascinating discovery that challenges fundamental assumptions in optical imaging. With that in mind, it’s worth describing what compressive sensing is, and why it could revolutionize the way we collect data!
To understand compressive sensing, we first take a (very crude) look at how an ordinary digital camera processes images. My current digital camera is a 10 mega-pixel (10 million pixel) camera. In short, this means that the camera consists of a system of lenses that form an image on a CCD (charge-coupled device) sensor consisting of a two-dimensional array of pixels. Each pixel converts the light incident upon it into an electrical current, which in turn is digitized. A magnified image of an edge of one of these arrays is shown below.

Edge of a CCD pixel array. Each pixel is approximately 0.01 mm across. (Via Warren Wilson College.)
So let’s look at how much information the camera actually captures. Assuming, for simplicity, that each pixel records 1 byte RGB (red, green, blue) values, we expect that a recorded image consists of 30 million bytes of raw data!
However, the images I actually download to my computer are much, much smaller: typically around 1 megabyte, though the actual size varies. This is a factor 30 smaller than the size of the raw dataset — what happened? After recording, the image was digitally compressed, a process in which the data is reorganized to isolate the important features and only these features are kept.
To give a simple idea of the feasibility of data compression, we look at my adaptation of a famous work of art, “Polar bear in a snowstorm”:

If we were to photograph this image with my camera, the “raw” data would be 30 million bytes. However, it is clear that the entire image could be described with a very small amount of information:
1) 3 bytes to describe the overall color of the background, namely white,
2) 2 bytes to describe the total number of ellipses in the picture,
3) roughly 13 bytes each to describe the position, shape, orientation, and color of each of the eyes and nose (4 bytes for center position of each ellipse, 4 bytes to describe the height and width of each ellipse, 2 bytes to describe the orientation of each ellipse, and 3 bytes to describe the color of each).
If our compression algorithm is designed to represent any picture as a combination of ellipses, then this is all of the information we need! A 30 million byte photograph can be reduced to roughly 44 bytes of information.
The take-away lesson here is that the pixel (point-by-point) data is being replaced in compression by what we might call “structural data”. In the case of our polar bear, we manage massive data compression by reinterpreting our picture in terms of a series of ellipses on a uniform background instead of a series of points.
The polar bear is a ridiculously simple image, however, and one might reasonably wonder if “real” images can be compressed so effectively. In 2008, programmer Roger Alsing inadvertently gave a great demonstration of this possibility when he used a genetic algorithm to construct a very accurate representation of the Mona Lisa from only 50 semi-transparent polygons!
A sample of his own simulation is shown below; the file number indicates the number of “generations” the image was allowed to evolve.

The total number of polygons is a little misleading, because it seems that the number of polygon sides was allowed to be arbitrarily large in the simulation. Nevertheless, a quite accurate representation of the Mona Lisa was produced with a surprisingly small amount of information. This genetic algorithm works as a very crude and inefficient form of image compression, replacing the large amount of pixel information in the image with a relatively small amount of structural information, namely an arrangement of polygons. (You can run a similar algorithm on your favorite pictures at this website.)
Many of the most common image compression algorithms work by the same strategy: they decompose the object into a collection of structures, ranked in order of how much they actually contribute to the image. Compression is achieved by “throwing away” any structures that contribute negligibly to the overall appearance of the image. This is known as lossy compression, as image information is being lost in the process; however, the information disposed of is relatively unimportant.
Such techniques work quite well, as can be seen by the success of digital photography. However, it is in a very real sense wasteful! My camera, for instance, has to record 30 million bytes of data (and contain 10 million sensors), even though I really only need about 1 million bytes of data to make a good picture. You might ask: is there a way to “cut out the middleman”, and directly record the 1 million bytes of important data with an optical system?
This is the general idea of compressive sensing in optics: instead of measuring a large amount of data and compressing it after measurement, we can design our optical system to directly measure only the important data. With, say, only a million cleverly-designed measurements we can reconstruct an image with the quality of a 10 megapixel camera!
The simplest compressive sensing strategy in optics is illustrated below, and is referred to as sequential compressive sensing [1], and literally only requires a single pixel to collect light! Light from a scene or object is imaged onto a programmable mask; the light that travels through this mask is collected by the detector.

The mask is the key: in the simplest incarnation it is an 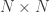
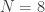
 The mask can be changed by computer, with different squares turned on and off. By repeatedly changing the mask and recording the amount of light that reaches our single pixel detector, we can eventually collect enough information to reconstruct the image via computer algorithm.
The mask can be changed by computer, with different squares turned on and off. By repeatedly changing the mask and recording the amount of light that reaches our single pixel detector, we can eventually collect enough information to reconstruct the image via computer algorithm.
You may have noticed that this mask, a two-dimensional grid, looks suspiciously like the CCD array that we pictured at the beginning of this post. You might reasonably suspect that I haven’t reduced the amount of data collected, but have only changed from having an 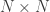
The difference, and the key to compressive sensing, is the choice of masks. It can be shown that with the correct selection of mask configurations, the number of measurements required to reconstruct an image is much, much less than the number of “pixels” in the mask.
It turns out that the optimal choice of masks are essentially random! Choosing random masks, where each “pixel” is randomly taken to be on or off within each mask, allows the reconstruction of the “essential” features of the image with a number of measurements much smaller than the effective number of pixels.
What is difficult to explain, however, is why a collection of random masks works much better than any other strategy! What follows is my crude way of thinking about it…
Suppose the image you want to reconstruct consists of 5 randomly colored and located pixels in a 
![]()
Clearly it would be a waste of effort to measure every pixel, since only 5 are colored; we expect that 5 good measurements, maybe 10, should be enough to reconstruct the image. But how do we choose those 10 measurements, since we don’t know where the colored pixels are? The worst thing we could do would be to just randomly sample 10 pixels, because the odds of us hitting all 5 pixels would be very small.
The best thing we can do is cast as wide a “net” as possible, using masks that extend over the entire image area, and have different pixels turned on and off, such as:

Each mask has a fair chance of catching at least one “on” pixel, and because each mask is different they each contain a different set of information about the image. No individual mask tells us anything certain about any specific pixel, but rather tells us something about the image as a whole.
The mathematics behind this process was first introduced in 2005 by Candes and Tao [2], and its significance to optics was almost immediately appreciated. Since then, an array of papers have come out in which compressive sensing principles are applied to every imaging and measurement system imaginable.
The serial measurement scheme described above works, but would be very slow to record an image, since the mask measurements need to be made one at a time. A faster technique involves using 

The masks described here are somewhat inefficient, in that they block a significant fraction of the light incident upon them, and that light is completely lost. Anyone who has ever taken a crappy digital photograph in a dark room can appreciate that light is sometimes hard to come by, and throwing it away is a very poor strategy! A less wasteful strategy for compressive sensing is to perform what is known as “photon sharing”, in which the mask is an array of polarization-changing elements.
I’ve discussed before (in basics posts) that light is a transverse wave; the electric field E and magnetic field H that comprise a light wave oscillate perpendicular to the direction of motion:

Looking at the wave head-on, the electric field can be oriented in any direction with respect to the horizontal or vertical axes; that orientation is what we usually refer to as “polarization”:

Optical devices can be constructed that are sensitive to polarization state; in particular, a polarizing beamsplitter is a device that reflects horizontal polarization while transmitting vertical polarization. An arbitrarily polarized beam will have its vertical component transmitted while having its horizontal component reflected.
If we use a set of masks that rotate the polarization direction instead of blocking light, we can choose to send a fraction of light from each mask pixel to a detector; the remaining light travels onward to another mask, where part of light at each pixel gets deflected to a detector, and so on. In the end, all light is collected by some detector along the line.

Instead of randomly blocking a certain amount of light at each pixel, the mask randomly “scrambles” the polarization of light at each pixel.
So why is compressive sensing considered extremely important? The first reason is economics: cameras with fewer pixels are cheaper! Compressive sensing has the potential to lower the price of imaging devices while at the same time improving their performance. The second reason is that many medical imaging techniques, such as MRIs and CAT scans, necessarily involve a limited number of measurements. Compressive sensing allows the possibility to get “more” information out of the limited data.
As I have said, it is unclear how much the technique will be used in future optical systems — it is still a very new technique and has not yet been implemented in commercial products, to my knowledge. It is nevertheless intriguing to think that the most significant discovery in optical imaging may involve taking less data, not more!
*****************
[1] M.A. Neifeld and Jun Ke, “Optical architectures for compressive imaging,” Appl. Opt. 46 (2007), 5293. My discussion of the optical strategies for compressive sensing are derived from this article.
[2] E.J. Candes and T. Tao, “Decoding by linear programming,” IEEE Trans. Inf. Theory 51 (2005), 4203-4315.
*****************
Some other resources:
R.G. Baraniuk, “Compressive sensing,” IEEE Signal Proc. Mag., July 2007, 118-214. A short introduction to the mathematics of compressive sensing.
E.J. Candes and M.B. Wakin, “An introduction to compressive sampling,” IEEE Signal Proc. Mag., March 2008, 21-30. A good introduction to the ideas of compressive sensing.
J. Romberg, “Imaging via compressive sampling,” IEEE Signal Proc. Mag., March 2008, 14-20. The application of compressive sensing to imaging.



There’s something very similar that goes on in multi-dimensional NMR, where experiments are expensive to perform, and so you want to maximize information (alt: minimize error) as a function of the number of experiments. A lot of work has been done recently in using MaxEnt methods to reconstruct signals from experiments designed this way. If you’re interested, I can go grab a few key refs.
I’d be interested to see it! I actually have a paper that describes the use of compressive sensing in MRI, in which it is acknowledged that the method by which MRIs are already measured is very amenable to compressive techniques.
If I remember correctly, this is roughly how the Rotating Modulation Collimator worked on the SAS-C satellite. The RMC was an imaging X ray detector that worked using a random X ray blocking shield and a single photomultiplier as its sensor. The random pattern was rotated for higher resolution. This let them take pictures of X-1 back before they had practical X ray lenses. (I helped made tee shirts of X-1 since my lab had a computer controlled color copier and oodles of toluene to transfer the fused toner.) They also considered moving the shield closer and further from the sensor to make a “trombone” RMC, perhaps for a future launch.
I had a roommate who was on the mission team, so I mainly heard about problems with the nutation damper and how the folks they shared the satellite with at SAO manged to aim one of the star cameras, used for positioning, at the sun and burned it out. It was like his kid brother was always bringing in the car on the fumes with a new dent in a door panel.
I’d be curious to know if they were actually using compressive sensing or just using a programmable mask to allow the use of a simpler detector. The devil is in the details, as they say: even without compressive sensing, one can use a programmable mask + “bucket detector” to act as a detailed image sensor. The “compressive” part is the mathematics that allows you to use far fewer mask configurations to get an image than you would expect…
so is that the difference between compressive sensing with a bucket detector, and “ghost imaging”, who’s setup is exactly the same??
I actually did a post on ghost imaging some time ago! The setups are similar, and I was a bit confused in fact about the relationship myself at first. I think you’re right that the essential difference is in the mathematics that allows compressive sensing to use less measurements. In fact, there’s a paper on “compressive ghost imaging”, which combines the techniques.
Pingback: "Another recent discovery, unnoticed by the public, will likely have an even… | mantulmantul.com
nice article: minor niggle. one sentence reads like all cameras use CCDs. Canon use CMOS.
http://en.wikipedia.org/wiki/Canon_EOS#Digital_cameras
Indeed! I’ll have to check the text to make sure I didn’t imply that *all* cameras are CCDs. I had done the research on it beforehand!
Copy edit: “\latex” should be “latex” (the formula isn’t parsing).
Ah, thanks — fixed! I may make some more revisions to the post later, as it was quite late at night when I finished it…
Interesting stuff. Do you know whether the resolution when using the lenslet array approach is limited by the size of the lenslets? Or is there some magic that gets around this limitation?
My impression is that the resolution is limited by the size of the lenslets. However, fewer lenslets are needed to construct a “bigger” picture.
Another question just occurred to me…. Given that it’s been shown that more information can be captured with fewer elements…. what if they used, say, way more elements in the LCD mask? Is there any potential for super-resolution with this stuff?
I’ve been wondering how to properly characterize it myself. In a sense, it is a type of “super-resolution”, in that it is usually described as beating the traditional Nyquist frequency limit. I haven’t gotten a good feel on what the limits are, however.
i would argue that Nyquist doesn’t apply here! and the “total bandwidth” recoverable will still follow Nyquist (total area under frequency graph can’t be greater than in Nyquist case).
I don’t completely appreciate the relationship between the Nyquist limit and compressive sensing, myself! I suspect that the argument is really that the Nyquist limit can be “beat” because of the existence of “prior knowledge” that roughly replaces the data not taken. This prior knowledge is, of course, the fact that the data is sparse!
Thanks for the link to the Lytro camera. When I read what the technology was doing, my first thought was “if they’re capturing the wavefront (sort of), then it should be able to do 3D reconstruction.” Sure enough, it can! Check out this demo of the Lytro’s 3D capabilities: http://youtu.be/D_aAqAvf43g
I don’t have a 3D monitor, but YouTube has a number of viewing options. The one that worked best for me was to set the 3D to “No Glasses” and use the “Parallel” option. You then look “through” the screen so that the two images merge into one (like MagicEye(TM) pictures).
So… what did you think about the *rest* of the post? 😉
Greg,
It is a good explanation. You might be interested in seeing how people want to use compressive sensing in other types of hardware:
https://sites.google.com/site/igorcarron2/compressedsensinghardware
to learn more how to use these techniques your readers might be interested in the following:
http://nuit-blanche.blogspot.com/p/teaching-compressed-sensing.html
Thanks for the links!
My biggest question about using compressed sensing in real life is how errors happen when your image isn’t actually compressible. supposedly, the least important information disappears, but it is VERY non-intuitive how artifacts pop up, and the way the Twist (or other) algorithm works is quite unpredictable. I even saw an example where they treated it as sparse dots in an image, and the result was almost correct, except one dot was completely in the wrong place. A very dangerous error for things like medical imaging,…
Sparsity and compressibility are just some of the preliminary prior information that are used nowadays. I can definitely foresee additional ones popping up as we continue on exploring the field: positivity of the signal being one of them.
I can see that! The field of compressive sensing is very young, and there’s plenty of prior knowledge that can hopefully be applied to minimize data collection. The use of prior knowledge has been extensively explored in lots of inverse problems in the past; the compressive technique is a more elegant “paradigm” (I try and avoid that word) to deal with it.
yes, in fact, positivity (of intensity measurements) is used in iterative phase retrieval, and is often (surprisingly) enough extra info to solve the problem in a lot of cases… i agree that compressive sensing is an elegant way to use prior knowledge – the mathematical proofs that it works being especially valuable.
I’m not sure how errors propagate in the system, but it’s a good question. It seems the technique is generally lossy, which could also be a significant problem for important medical problems.
LW asks “so is that the difference between compressive sensing with a bucket detector, and “ghost imaging”, who’s setup is exactly the same??”
They are not exactly the same. Please note the computer in the compressive ghost imaging set up (see arxiv paper). Also as Greg said, the number of measurements is more precisely known and the reconstruction solver is
– not analog
– based on the underlying fact that the image is sparse in some fashion.
Click to access 0905.0321v1.pdf
Igor.